Los sistemas Big Data tienen un conjunto de características que los hacen únicos:
- Volumen: el volumen de los datos son de gran tamaño
- Demasiado grandes para caber en memoria principal.
- Si está indexado, sus índices pueden ser demasiado grandes para la memoria principal.
- Velocidad: los datos se generan o nos llegan muy rápido y deben procesarse rápidamente
- Variedad: hay muchos tipos diferentes de datos
- Los datos ya no tienen las estructuras relativamente estables del pasado
- Por ejemplo, registros de transacciones financieras en una base de datos relacional.
- Otras características que pueden presentar:
- Veracidad: ¿Son los datos relevantes y significativos para la necesidad del proyecto?
- Validez: es la información correcta y precisa para su uso
- Volatilidad: cuánto tiempo son válidos los datos y cuánto tiempo se deben almacenar
Basados en estas características, los sistemas Big Data debe cumplir con un conjunto de objetivos de cara a permitir su procesado:
- Proporcionar un alto rendimiento y capacidad de almacenamiento
- Proporcionar fiabilidad muy alta
- No debe existir un solo punto de fallo
- Escalar horizontalmente
- Debe permitir añadir más máquinas cuando se necesite escalar
- Utilizar máquinas básicas que sean económicas (en lugar de máquinas especializadas de alta potencia, esto es escalado vertical)
- Debe permitir añadir más máquinas cuando se necesite escalar
Para lograr estos objetivos se usan muchas técnicas, entre ellas las de replicación y sharding (o particionado).
MongoDB es un producto NoSQL permite implementar ambas técnicas proveyendo mecanismos de replicación y sharding de fábrica.
Replicación en Mongo
Mongo permite la replicación de datos para redundancia y alta disponibilidad.
Consiste de un conjunto de réplicas, que son un conjunto de instancias que hospedan el mismo set de datos.
Dentro del conjunto existirán instancias o nodos primarios y secundarios, tal como se muestra en el siguiente esquema:
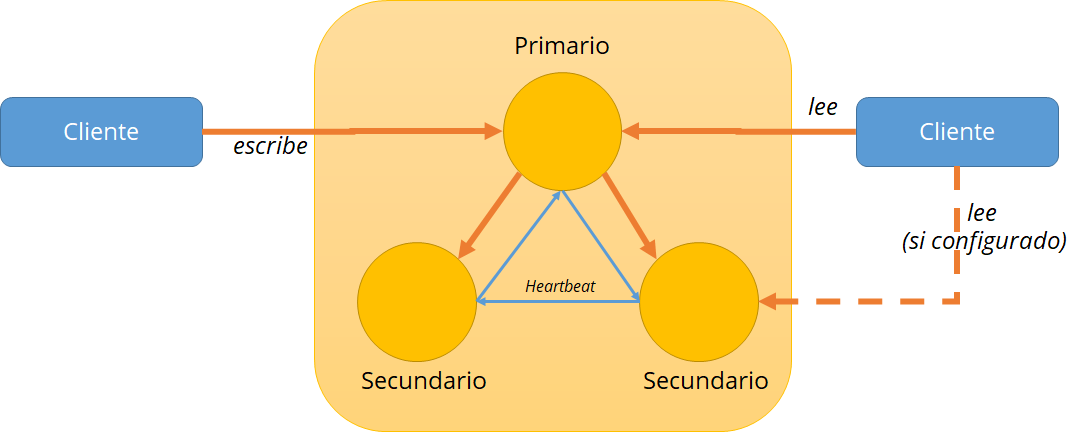
La replicación está configurada en el nivel de cada instancia de MongoDB
Nodo Primario: acepta todas las operaciones de escritura del cliente
- Por defecto, acepta todas las operaciones de lectura
- Solo un elemento primario en un conjunto de réplicas
- Si falla un primario, el conjunto de réplica elige un nuevo primario
Nodos Secundarios: replica el conjunto de datos de las primarias
- Actualizaciones propagadas asincrónicamente a secundarios
- De forma predeterminada, solo copias de seguridad de las instancias sin servicio de solicitudes
- Puede configurarse para aceptar solicitudes de lectura, pero no de escritura
Heartbeats (latidos): Los miembros del conjunto réplica envían latidos (pings) cada dos segundos. Si un latido no regresa dentro de los 10 segundos, los otros miembros marcan al miembro delincuente como inaccesible.
En caso de que el primario sea inaccesible, el algoritmo de elección hará un intento de «mejor esfuerzo» para que el secundario con la prioridad más alta disponible invoque una elección y se elegirá un nuevo primario.
Habilitando la replicación en Mongo
Simularemos la replicación en una sola máquina a efectos de este tutorial. En producción se haría con tres máquinas diferentes, con permisos para acceso desde las otras máquinas y las carpetas de base de datos en cada máquina.
Seguiremos el siguiente procedimiento para la replicación:
1. Primero definiremos las instancias
a. Para ello deberemos crear 3 carpetas:
| mkdir repl_1 repl_2 repl_3 |
b. Lanzamos las instancias. Para ello abre tres ventanas de consola y escribe
| #ventana 1mongod –replSet rs0 –dbpath /repl_1 –port 27017#ventana 2mongod –replSet rs0 –dbpath /repl_2 –port 27018#ventana 3mongod –replSet rs0 –dbpath /repl_3 –port 27019 |
c. Nos conectamos con 3 clientes. Para ello abre otras 3 ventanas de consola:
| #cliente 1mongo#cliente 2mongo –port 27018#cliente 3mongo –port 27019 |
2. Generaremos la configuración de replica
a. En el cliente 1 escribe:
| var rsconf = {_id: «rs0»,members: [{_id: 0,host: ‘localhost:27017’},{_id: 1,host: ‘localhost:27018’},{_id: 3,host: ‘localhost:27019’}]}; |
b. Luego inicializamos el conjunto de réplicas:
| rs.initiate(rsconf); |
c. Verificaremos el estado de las réplicas:
| rs.status(); |
3. Habilitaremos los secundarios para que acepten replicas
a. En cada secundario y acepta el estado de secundario
| #cliente 2rs.slaveOk();#cliente 3rs.slaveOk(); |
Probando el conjunto
Ahora probaremos el conjunto:
- Crea una base de datos, una colección e insertaremos datos en el primario:
| use shipsdb;db.ships.insert({name:’USS Enterprise-D’, operator:’Starfleet’, type:’Explorer’, class:’Galaxy’, crew:750, codes:[10, 11, 12]});db.ships.insert({name:’USS Prometheus’, operator:’Starfleet’, class:’Prometheus’, crew:4, codes:[1, 14, 17]}); db.ships.find(); |
- Comprueba la réplica en los secundarios:
| show collections; use shipsdb; db.ships.find(); |
Ahora deshabilitaremos el primario para validar que los secundarios se reorganizan para que uno se haga primario
- Tira el nodo primario: en la consola #1 haz CTRL-C
- Verifica los secundarios
| rs.status(); |
- Uno de ellos se debe marcar como nuevo primario
- Inserta datos en el nuevo primario
| use shipsdb; db.ships.insert({name:’USS Defiant’, operator:’Starfleet’, class:’Defiant’, crew:50, codes:[10, 17, 19]}); db.ships.insert({name:’IKS Buruk’, operator:’ Klingon Empire’, class:’Warship’, crew:40, codes:[100, 110, 120]}) ;db.ships.insert({name:’IKS Somraw’, operator:’ Klingon Empire’, class:’Raptor’, crew:50, codes:[101, 111, 120]}); db.ships.find(); |
- Comprueba en el secundario
| use shipsdb;db.ships.find(); |
Levantaremos nuevamente el primario para verificar que el conjunto se reorganiza:
- Vuelve a levantar el primario: para ello inicialízalo:
| #ventana 1mongod –replSet rs0 –dbpath /repl_1 –port 27017 |
- Verifica su situación y si no es primario acepta como secundario
| #cliente 1mongors.status();rs.slaveOk(); |
| use shipsdb;db.ships.find(); |
- Verifica que los datos se han actualizado en el nodo recientemente levantado (los datos insertados cuando estaba caído deben aparecer)
Reflexiones finales
La replicación Mongo da soporte a la alta disponibilidad; viene de fábrica y; es sencilla de configurar e implementar, pero tiene algunas limitaciones:
- En caso de fallo del primario, ocurre el failover (conmutación debido a error)
- Esto está automatizado en MongoDB, pero le toma un tiempo para que ocurra. Esto dará problemas de disponibilidad.
- La replicación no ayuda mucho con la escalabilidad.
- Las escrituras siempre se hacen en el primario, los secundarios no pueden compartir esta carga
- La carga de lectura se puede compartir con los secundarios, pero con pérdida de consistencia
- No hay mucha configuración para la replicación
- Se hace en el nivel de la instancia – no se puede sintonizar por colección
- Asimismo no se puede ajustar la consistencia si se comparten las lecturas.
En el siguiente artículo veremos cómo configurar Mongo en modo sharding, lo cual le dará más opciones a nivel de disponibilidad y añadirá escalabilidad.