Dabbawalas VS LEAN Services (II). El flujo del trabajo
Walter Henriquez
En un post anterior planteaba las similitudes que veía entre ambos “mundos” (Lean Services y dabbawalas), y me centraba en la organización de los equipos. Sin embargo ¿Cómo consiguen que las entregas sean tan eficientes?
El flujo de trabajo y el proceso de entrega
Usando el mismo vídeo de referencia, si vamos al minuto 53:20 se puede apreciar el flujo o viaje general que realiza cada daba:
Como se puede apreciar en la imagen, las dabbas se van aproximando al punto de asignación o reparto desde los domicilios del cliente. Cada daba lleva una marca que indica el punto de entrega , donde los dabbawalas las asignan al grupo adecuado según la codificación de destino usada.
La codificación, que al fin y al cabo marca el destino, es muy sencilla (¿POKA YOKE?) y muy visual. Un error de asignación de dabba salta a la vista de forma rápida gracias a la mezcla de uso de letras, números y ¡colores! Esta sencillez (Complexity opposes compliance) provoca que todos los trabajadores colaboren en la detección de posibles errores y se rectifique de forma rápida (¿Andon?), el propio proceso incorpora los elementos de control de calidad (¿Jidoka?).
Como se puede ver, algunos conceptos LEAN están muy asimilados en el proceso de control del “viaje” de una dabba:
POKAYOKE: A prueba de errores
Andon: Alerta de problemas
Jidoka: Automatización con un toque humano
El proceso productivo es de una sencillez y una lógica aplastante. Se delega el control del flujo a la primea línea (FrontLine) dotándola de los recursos para rectificar y “repara” la avería. Si nos vamos a LEAN manufacturing os invito a ver estos videos:
La clave para asegurar el flujo es que el equipo se sienta importante (¡y lo sea!) dentro del flujo de producción y pueda anticiparse a errores. Los procesos productivos debe incluir sistemas de autocontrol de calidad, no para detectar errores realizados, si no para evitar que estos errores se produzcan.
Llevando esto al modelo IT, por ejemplo Gestión de Incidencias, cada Task Force (ver post anterior) debe ser semiautónoma y controlar el estado de cada una de las incidencias que tiene a “su cargo”. Si la incidencia está a punto de “salir de los niveles de calidad” debe ser priorizada por el propio equipo, pero mejor si hemos controlado el flujo de la incidencia desde su origen para evitar problemas futuros (si la incidencia no se pone “naranja” mejor…). Cada Task Force de gestión de incidencias debe tener “visible” el estado de cada incidencia. Los paneles de control general de estado de incidencias que se usan habitualmente están muy bien pero deben pasar al plano operativo y estar a “la vista de cada equipo” pero sólo aquello que importa. Actualmente tenemos una saturación importante de datos, los paneles de control llenos de datos, de los cuales sólo importan uno o dos. Os pongo un ejemplo que me contaron hace tiempo de proceso controlado a nivel operativo y proceso controlado a nivel de management y los resultados obtenidos.
Una compañía aérea estaba preocupada por los retrasos en los vuelos. Si un vuelo llega tarde tienen sobrecoste por penalizaciones e indemnizaciones, pérdida de slot aéreo, impacto en satisfacción de cliente, imagen…etc. Además, que un vuelo llegue tarde significa que otro que use el mismo avión puede salir tarde, provocando un efecto en cadena. Por ello la dirección de la compañía controlaba un indicador KPI: “Vuelos que han llegado con retraso”, tomando decisiones “off line” para mejorar en el siguiente ciclo. Lo malo es que los clientes afectados ya estaban afectados. Se decidió cambiar el indicador por uno llamado “Aviones en vuelo que van con retraso”. Este cambio es realmente importante, pues un indicador KPI offline pasó a ser totalmente en tiempo real. Tomar decisiones en tiempo real para hacer que ese avión llegue sin retrasos o con impacto mínimo en otros vuelos, significa dotar a FrontLine del poder de decisión adecuada para rectificar el proceso. Acababan de meter los sistemas de control de calidad dentro del propio proceso productivo (¿Andon, Jidoka?). Este sistema solo funciona si el equipo de control de vuelos de la compañía tiene sentimiento de equipo, se siente participe del proceso y se identifica con el servicio al cliente…como los dabbawalas, como la trabajadora de Toyota del video…
¿Y si en vez de revisar el informe diario/semanal/mensual de estado de incidencias dotamos, además, a las Task Forces de capacidad para cambiar prioridades y asignaciones para resolver en tiempo real?. Un ejemplo rápido, si sabemos que el tiempo medio en conversación de un operador es de 5 minutos, una vez la llamada supera el umbral X, el Team Leader (Task Forces) debe ver una alerta “visible” que le permita asignar recursos al operador (ayuda de otro operador, etc..) para solucionar más rápido. Este punto es especialmente importante, por ejemplo, cuando entran operadores junior, con mayor necesidad de tutorización en aquellos Service Desk que dan mucha importancia a la resolución en primera llamada.
Pronto seguiremos con esta serie de posts.
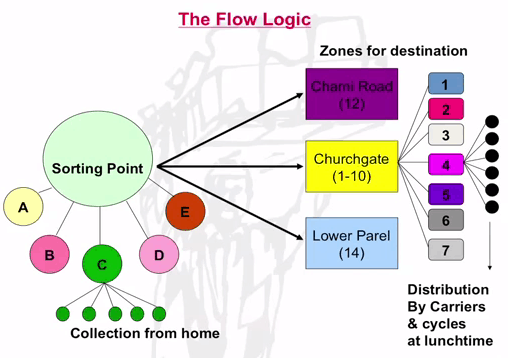 Como se puede apreciar en la imagen, las dabbas se van aproximando al punto de asignación o reparto desde los domicilios del cliente. Cada daba lleva una marca que indica el punto de entrega , donde los dabbawalas las asignan al grupo adecuado según la codificación de destino usada.
Como se puede apreciar en la imagen, las dabbas se van aproximando al punto de asignación o reparto desde los domicilios del cliente. Cada daba lleva una marca que indica el punto de entrega , donde los dabbawalas las asignan al grupo adecuado según la codificación de destino usada.
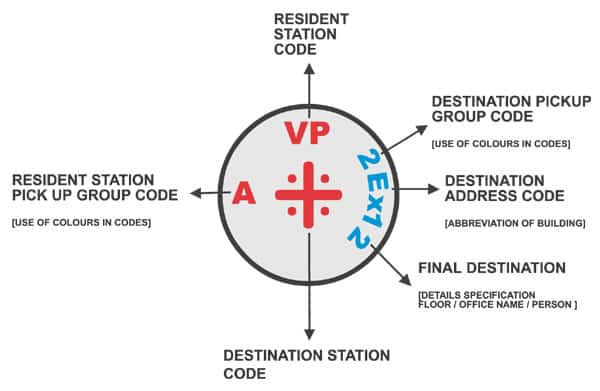 La codificación, que al fin y al cabo marca el destino, es muy sencilla (¿POKA YOKE?) y muy visual. Un error de asignación de dabba salta a la vista de forma rápida gracias a la mezcla de uso de letras, números y ¡colores! Esta sencillez (Complexity opposes compliance) provoca que todos los trabajadores colaboren en la detección de posibles errores y se rectifique de forma rápida (¿Andon?), el propio proceso incorpora los elementos de control de calidad (¿Jidoka?).
Como se puede ver, algunos conceptos LEAN están muy asimilados en el proceso de control del “viaje” de una dabba:
La codificación, que al fin y al cabo marca el destino, es muy sencilla (¿POKA YOKE?) y muy visual. Un error de asignación de dabba salta a la vista de forma rápida gracias a la mezcla de uso de letras, números y ¡colores! Esta sencillez (Complexity opposes compliance) provoca que todos los trabajadores colaboren en la detección de posibles errores y se rectifique de forma rápida (¿Andon?), el propio proceso incorpora los elementos de control de calidad (¿Jidoka?).
Como se puede ver, algunos conceptos LEAN están muy asimilados en el proceso de control del “viaje” de una dabba: